How to use AI to improve the architecture of your app
When a codebase start to become very large, it is very important to make the right decisions about the architecture of the software. Unfortunately, due to the pressure to develop and the deploy new features as fast as possible, the engineers don’t have time to evaluate and improve the architecture of their apps.
With some many new developments of AI tools, shouldn’t we have a way to leverage the power of AI to help us choose and implement better architecture practices faster?
When I first thought about this question the first thing it came to my mind was: how can I upload my whole codebase to a LLM? What are the limits of it? Should I brake my entire codebase into different chunks and use a RAG approach? With the new models arriving with insane amounts of context-windows, shouldn’t I just put the content of all my files as the input?
And then I realised that I have no idea of how big my codebase is. I know it’s huge but I don’t know how many files it has. I don’t know how many chars it has. I have no idea of how many tokens my codebase would be to even understand if I should use RAG instead of the LLM context window.
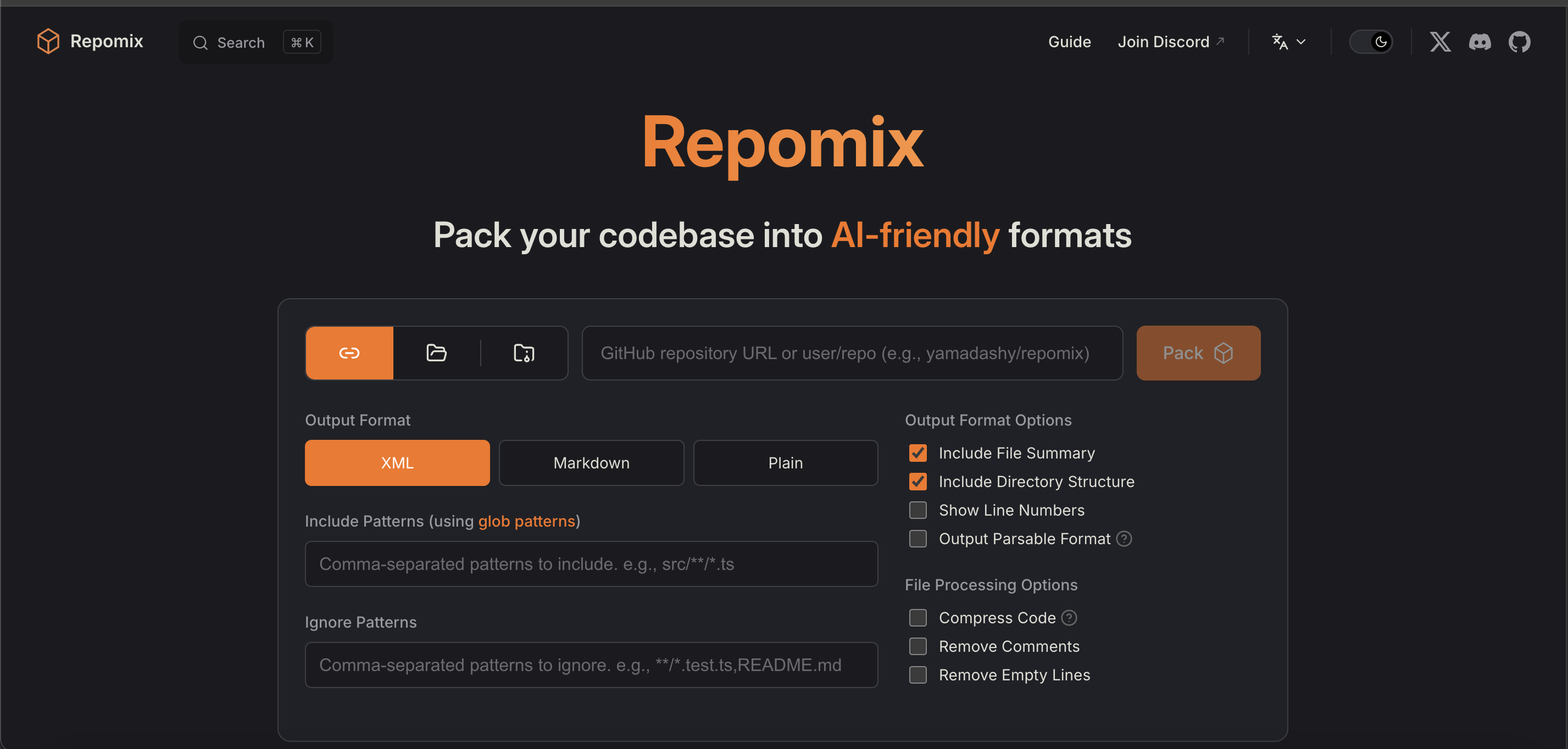
Lucky I am a very curious person and I love to hang out in online forums about tech and ai. In one of those forums I saw someone talking about a tool to do exactly that: get your repo content and create a file ready for LLMs to evaluate the content of it. I present you Repomix!

This is as simple as it can be. You can either go to the site and put your repo url or you can run it as a cli on your terminal using npx repomix.
This will generate a single .xml file with all your repo content and files. If you run it on the terminal it will also count how many files and chars you codebase has and give you also an estimation of how many tokens your codebase will take on a LLM context-window. This is perfect! When I run it on my project I got the following result:

For me the most important part was to know how many tokens it will be so I can understand if I can just pass it to a LLM without the need of RAG or any other technique. Now that I know how many tokens my codebase has, I can choose the right LLM to try it on.
During my research I learned that Google Gemini models are known for having huge context windows ( 1M tokens ) and I can use them for free. Nice. Now I had a xml file with the content of all my repo including the source code and the path of the files which can be used to feed it to a LLM and ask for improvements. My first try was to use the Gemini App and make a prompt asking it to examine my source and give me directions on improving the architecture, paste the content with the goold old Ctr + V / Ctrl + V and hit the button. It couldn’t be easier. Indeed, it was to good to be true.
When I tried to copy and paste directly the contents of the file on the Gemini App input, I pretty much broke the application because of the huge immense amount of information contained on that file:

Ok, fair enough. The codebase had more than 2 million chars. What did I expect? Well I remember that Google has Notebook LM, which is a tool that allows you to upload a file and create an ai chat on the content of your files. It is perfect. I will use it then. But there was just one problem: the tool has no support for xml files. It only support PDFs and .txt files. When I opened the xml file generated by Repomix I realised that it is just a regular text file with some extra formatting. So why I just don’t change it’s mime type to .txt and upload it?
Well, it worked!

This is perfect. Now I have an AI that can access the whole content of my codebase and give me insights on how to improve it’s performance, architecture, file-structure, anything.
I decided to give it a try with the following prompt:
the file is a representation of a github repo containing the source code of a react based web app. This app is structured in different workspaces. The objective of the app is to allow users to collect data for a given company and use this data to create esg reports. The admin user can request data to employees of the company by adding them in the company workspace and requesting information in different types. Based on the content of the repo I gave you, how can I improve the architecture of this app?
The result was incredible. In the answer the AI was capable to understand the current architecture, file structure, workspaces, separation of concerns, classes, interfaces, states and give me a comprehensive answer and insights on improvements I could make.
It was exactly what I was looking for. Mission completed!

Conclusion:
It is possible to feed your codebase to a LLM and get insights of it. But it’s important to keep in mind the limitations. In my approach I tried with a codebase under 1 million tokens. Depending on your codebase size, maybe this approach might not work as expected. It is also important to have in mind that you should be able to assess and evaluate the answers given by the AI. Taking a codebase that you don’t know and just trust an AI to make decisions and follow them blindly is something I would never encourage. I think is important to keep curious, try and share new approaches. But we also need to keep in mind that in the end, a good Software Engineer has to be able to evaluate any decision, wether it was proposed by a machine or by a human.



Leave a Reply